Soon all this material will find a home in a more appropriate place. In the meantime, enjoy the lecture!
While testing large tables, it is useful to test if two tables have the same contents. For example, if you want to compare performance between two tables using different storage engines, or tables created on different filesystems, you must be sure that both tables have the same content. Having loaded both from the same source is not a guarantee that the contents are the same: a mistake or different SQL modes used during the load may result in substantial differences.
General concepts
Then, you need to compare two, possibly very large tables. There are several methods available. One is to run a query with a LEFT OUTER JOIN. However, this method is likely to take very long or even exhaust your system resources if your tables are really large.One method that I have been advocating for long time is to run a global CRC on both tables and then compare the results.
And, I hear you asking, how do you get a global table CRC?
There is no predefined SQL feature for this task. Recent MyISAM tables have a built-in CRC, but you can't get it from a SELECT statement, and besides, if you need to compare the contents of such a table with one using a different engine, you are out of luck. Then, we need to use something more general, which can be applied to any table.
The first step to get a global CRC is to get a list of the columns that we can then pass to a CRC function such as SHA1 or MD5.
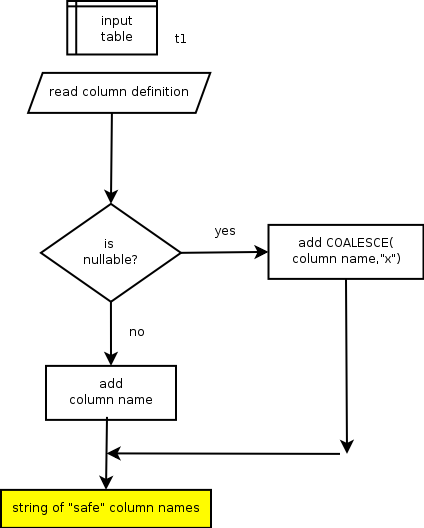
This list is a string made of the name of the columns, which we will pass to a CONCAT_WS function. However, if you know how SQL functions work, you will know that any NULL value in the list will nullify the whole expression. Therefore, we need to make sure that every nullable column is properly handled by a COALESCE function. The result of this operation, which we delegate to a stored function, is a safe list of column.
The second step towards a global table CRC is to calculate a CRC for each record. We use the above list of columns to create a SELECT statement returning a SHA1 for each record in the table. But, what to do with it? There is no aggregate SQL function available for SHA or MD5. Thus, we need to process the result and calculate our CRC manually.
As noted in a previous post, we can do that in two ways, using cursors or using a blackhole table. Some benchmarks show that the blackhole table is much faster than the cursor, and this is what we do.
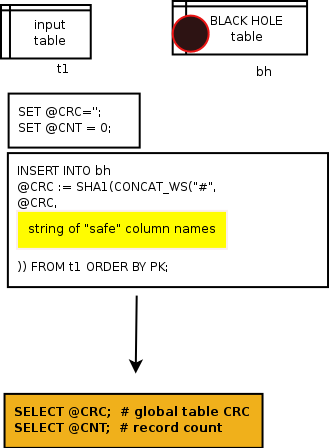
We start with an empty CRC. For each row, we compute a CRC of the whole record, plus the existing CRC. Since we are using a SELECT statement, we need to get rid of the output, because we are only interested in the calculation stored in the user variable. For this purpose, a black hole table is very well suited. At the end of the SELECT + INSERT operation, we have in hand two variables, one showing the count and one holding the global CRC for the table.
Repeating this process for the second table we need to compare, we can then compare two simple values, and determine at a glance if we are dealing with comparable data sets.
Implementation
Let's put the concepts together with a few stored routines.The first function returns a safe list of column names.
delimiter //
drop function if exists get_safe_column_list //
create function get_safe_column_list
(
p_db_name varchar(50),
p_table_name varchar(50),
p_null_text varchar(20)
)
returns varchar(10000)
reads sql data
begin
if ( @@group_concat_max_len < 10000 ) then
set group_concat_max_len = 10000;
end if;
return (
select
group_concat( if(is_nullable = 'no', column_name,
concat("COALESCE(",column_name, ", '", p_null_text,"')") ))
from
information_schema.columns
where
table_schema= p_db_name
and
table_name = p_table_name
);
end //
drop function if exists get_primary_key //The second routine returns a table primary key, as a list of column.
create function get_primary_key (
p_db_name varchar(50),
p_table_name varchar(50)
)
returns varchar(10000)
begin
if ( @@group_concat_max_len < 10000 ) then
set group_concat_max_len = 10000;
end if;
return (
select
group_concat(column_name order by ORDINAL_POSITION)
from information_schema.KEY_COLUMN_USAGE
where
table_schema=p_db_name
and table_name = p_table_name
and constraint_name = 'PRIMARY' );
end //
drop procedure if exists table_crc //The third procedure returns the global CRC of a given table.
create procedure table_crc (
IN p_db_name varchar(50),
IN p_table_name varchar(50),
OUT p_table_crc varchar(100)
)
reads sql data
main_table_crc:
begin
declare pk varchar(1000);
declare column_list varchar(10000);
set pk = get_primary_key(p_db_name, p_table_name);
set column_list = get_safe_column_list(p_db_name, p_table_name, 'NULL');
if (column_list is null) then
set p_table_crc = null;
leave main_table_crc;
end if;
set @q = concat(
'INSERT INTO bh SELECT @tcnt := @tcnt + 1, ',
'@tcrc := SHA1(CONCAT(@tcrc, CONCAT_WS("#",', column_list, ')))',
' FROM ', p_db_name, '.', p_table_name,
if (pk is null, '', concat(' ORDER BY ', pk))
);
drop table if exists bh;
create table bh (counter int, tcrc varchar(50)) engine = blackhole;
set @tcrc= '';
set @tcnt= 0;
prepare q from @q;
execute q;
set p_table_crc = concat(@tcnt,'-',@tcrc);
deallocate prepare q;
end //
drop procedure if exists table_compare //The final routine puts all pieces together, returning a boolean value telling if the two tables have the same contents.
create procedure table_compare (
IN p_db_name1 varchar(50),
IN p_table_name1 varchar(50),
IN p_db_name2 varchar(50),
IN p_table_name2 varchar(50),
OUT same_contents boolean
)
begin
declare crc1 varchar(100);
declare crc2 varchar(100);
call table_crc(p_db_name1,p_table_name1, crc1);
call table_crc(p_db_name2,p_table_name2, crc2);
select concat(p_db_name1, '.', p_table_name1) as table_name, crc1 as crc
union
select concat(p_db_name2, '.', p_table_name2) as table_name, crc2 as crc ;
set same_contents = (crc1 = crc2);
select crc1=crc2 as 'same contents';
end //
delimiter ;
Testing
After loading the above code in our database, we can call a "table_crc" procedure to get our coveted value. Let's take the famous world database and let's give it a try.
mysql> use world;
Database changed
mysql> create table City2 like City;
Query OK, 0 rows affected (0.03 sec)
mysql> alter table City2 ENGINE = InnoDB;
Query OK, 0 rows affected (0.09 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> insert into City2 select * from City order by District, population;
Query OK, 4079 rows affected (0.33 sec)
Records: 4079 Duplicates: 0 Warnings: 0
First of all, we create another table, with the same structure of City, but using a different engine, and storing data in a bizarre order to see if our routine is robust enough. In fact our routine will calculate the CRC after sorting the data by primary key, so that there won't be any surprise.
mysql> call table_crc(schema(), 'City', @city_crc);
Query OK, 0 rows affected, 1 warning (0.16 sec)
mysql> select @city_crc;
+-----------------------------------------------+
| @city_crc |
+-----------------------------------------------+
| 4079-407840fbf812b81eee55d3a438cf953f81c63bc0 |
+-----------------------------------------------+
1 row in set (0.00 sec)
mysql> call table_crc(schema(), 'City2', @city2_crc);
Query OK, 0 rows affected (0.13 sec)
mysql> select @city2_crc;
+-----------------------------------------------+
| @city2_crc |
+-----------------------------------------------+
| 4079-407840fbf812b81eee55d3a438cf953f81c63bc0 |
+-----------------------------------------------+
1 row in set (0.01 sec)
When we compare the CRC, we can easily see that the two tables are the same. If all these statements are tedious to write, we can use a shortcut:
Le'ts make it fail, to see if it is true:
mysql> call table_compare(schema(), 'City',schema(), 'City2', @same);
+-------------+-----------------------------------------------+
| table_name | crc |
+-------------+-----------------------------------------------+
| world.City | 4079-407840fbf812b81eee55d3a438cf953f81c63bc0 |
| world.City2 | 4079-407840fbf812b81eee55d3a438cf953f81c63bc0 |
+-------------+-----------------------------------------------+
2 rows in set (0.24 sec)
+---------------+
| same contents |
+---------------+
| 1 |
+---------------+
1 row in set (0.24 sec)
mysql> update City2 set population = population + 1 where id = 1;Now the two tables will have at least one difference:
Query OK, 1 row affected (0.05 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> call table_compare(schema(), 'City',schema(), 'City2', @same);And our routine finds it. QED.
+-------------+-----------------------------------------------+
| table_name | crc |
+-------------+-----------------------------------------------+
| world.City | 4079-407840fbf812b81eee55d3a438cf953f81c63bc0 |
| world.City2 | 4079-b3b613b20570024be727ef0454053a96cfc36633 |
+-------------+-----------------------------------------------+
2 rows in set (0.23 sec)
+---------------+
| same contents |
+---------------+
| 0 |
+---------------+
1 row in set (0.23 sec)




5 comments:
So.. the obvious weakness of this is that it can't tell you what or where the differences are. I've seen other examples of queries that can, but they all compare each value in every row - which can obviously be very slow / resource intensive compared to this method.
If I needed to compare two very large tables, that are identical except for maybe 1 - 100 rows of data (some changed, some new, some deleted rows). I was wondering if it would be quicker to use the technique that you've shown here on the tables, then if differences are found, split the tables in half and run it again on just the first half - if changes are found there, split it again and repeat, otherwise move onto the second half. Keep splitting the data down into smaller sets to identify (maybe to within 1? 10? 100? rows?) where the changes actually are.
This way you can identify huge chunks of data that are exactly the same and don't need to be analyzed further, and small sections that contain changes, on which the other methods (compare each value) can be run far more efficiently.
I'm fairly new to SQL, so this sort of thing is a bit beyond my current capabilities, but I think this would be a really nice approach (in theory) to doing data comparisons.
I'd be interested in your thoughts on this idea ;)
The purpose of this technique is just to find if there are any differences. This is useful when you are comparing tables that are produced by replication, clustering, data copy, and so on.
However, if you need to find out exactly where is the difference, I wrote an article about this subject a few years ago, where I tried the approach that you describe, and found out that it's quite inefficient. There is a different algorithm you can use, i.e. taking the CRC of small chunks of the table, grouped by a convenient column value, and then apply a binary search to the differing chunks only, until you find the single rows that you are after.
There are 2 problems with this approach:
1. a fixed string is substituted for NULL values. If this string appears as a column value, we could get the same crc value for substantially different row values
2. column values are concatenated before the crc is computed. Therefore a row containing ("some", "data") would give the same crc as one containing ( "so", "medata").
A more robust crc method is to produce the sha1 of each column, and to separately include the NULL status of each:
select sha1( concat( if(c1 is null,1,0), sha1(ifnull(c1, '')), if(c2 is null,1,0), sha1(ifnull(c2,'')),...))
This way we can distinguish between NULL columns and those containing empty strings, and also avoid problems with different column values concatenating to the same row value.
Martin,
The first comment is correct, although the given stored routines accepts a string that you want to replace the null with, so you may use the value that makes most sense.
The second comment is not correct. I am using CONCAT_WS, not CONCAT. Thus "so" "medata" and "some" "data" will be concatenated differently. (so#medata vs. some#data)
Giuseppe
Giuseppe,
It is admittedly contrived, but the following both produce the same value:
select concat_ws( '#', 'some#', '#data' );
select concat_ws( '#', 'some##','data' );
regards,
Martin
Post a Comment