 | Everybody is moving to cloud architectures, although not all agree on what cloud computing is. In my limited understanding, and for the purpose of my work, cloud computing is a quick and versatile availability of virtual machines.
Now, if my purpose was deploying these machines, a private cloud in one host (namely, my laptop) would not make sense. But to create a flexible testing environment, it works very well.
Users of virtual machines software such as VMWare or VirtualBox may ask what's new here. You can create many virtual machines and use them within the same host.
True, but creating a new virtual machine in one minute without duplication of resources is not so easy. This is what this article covers. More specifically, it covers how to clone virtual machines efficiently with VMWare Fusion on a Mac OSX laptop. |
I have been a VMWare user for more than 10 years, mostly on Linux, where I used VMWare Workstation. One of the features that I liked on that application was the ability of cloning virtual machines, where the clones share the disk with the original VM. VMWare Fusion does not have a cloning feature, but there are ways of achieving the same result.
If you copy a virtual machine and then open it with Fusion, it will ask you if you have copied it, and after your answer, it will use the new virtual machine independently from the first one. The only problem is that you will have twice as much disk space occupied. So, in addition to the space that will eventually got eaten up in your limited laptop, the duplication process is slow (copying 10 GB does not happen instantly). The method shown here will instead allow you to clone a virtual machine in less than one minute.
Part I - How to clone a virtual machine
I have got this recipe from
HOWTO: Manual Linked Cloning in Fusion, a year old tutorial that I have integrated with updated images.
Do it once - Create a virtual machine with everything you need.
This is a once only step. Install a virtual machine as usual. In my case, I used Ubuntu server 10.10. When I said
with everything you need I mean making sure that everything you think it will be necessary should be installed in this base VM. If you don't, you may end up installing the same thing in every cloned virtual machine.
What I did was updating the software, then installing the
build-essential package and the VMWare tools, and then enabling the "partner" repository to install the original Sun Java packages instead of the default OpenJDK. Next, I downloaded the source code for MySQL 5.5 and made sure that I had all the software necessary to compile and build the database.
Finally, I updated the CPAN with my favorite modules, stopped the virtual machine, and I was ready for the next step.
What I had in my hands was a working virtual machine. In order to make it clonable, I will go through some basic steps.
Step 1. Copy the VM disks
I create a new directory under the same path where the normal virtual machines are. I called it
ub_srv_10_base, and I copied the .vmdk files into this new directory.
Step 2. Modify the base disk to refer to fixed paths
In each virtual machine, the disk that has the same name as the VM (without numerals) is a sort of index of the real files containing the data. This file needs to be edited for further usage. Originally, it looked like this:
# Disk DescriptorFile
version=1
encoding="UTF-8"
CID=f88ac433
parentCID=ffffffff
isNativeSnapshot="no"
createType="twoGbMaxExtentSparse"
# Extent description
RW 4192256 SPARSE "ubuntu_server_10-s001.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s002.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s003.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s004.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s005.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s006.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s007.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s008.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s009.vmdk"
RW 4192256 SPARSE "ubuntu_server_10-s010.vmdk"
RW 20480 SPARSE "ubuntu_server_10-s011.vmdk"
# The Disk Data Base
#DDB
ddb.toolsVersion = "8323"
ddb.virtualHWVersion = "7"
ddb.longContentID = "d14a2f23de35287969b8eaebf88ac433"
ddb.uuid = "60 00 C2 98 72 3b 6e 76-ff 05 b7 ff 8a 07 6e 92"
ddb.geometry.cylinders = "2610"
ddb.geometry.heads = "255"
ddb.geometry.sectors = "63"
ddb.adapterType = "lsilogic"
To make it usable, I added a relative path to the file names, and removed the UUID.
# Disk DescriptorFile
version=1
encoding="UTF-8"
CID=f88ac433
parentCID=ffffffff
isNativeSnapshot="no"
createType="twoGbMaxExtentSparse"
# Extent description
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s001.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s002.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s003.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s004.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s005.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s006.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s007.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s008.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s009.vmdk"
RW 4192256 SPARSE "../ub_srv_10_base/ubuntu_server_10-s010.vmdk"
RW 20480 SPARSE "../ub_srv_10_base/ubuntu_server_10-s011.vmdk"
# The Disk Data Base
#DDB
ddb.toolsVersion = "8323"
ddb.virtualHWVersion = "7"
ddb.longContentID = "d14a2f23de35287969b8eaebf88ac433"
# ddb.uuid = "60 00 C2 98 72 3b 6e 76-ff 05 b7 ff 8a 07 6e 92"
ddb.geometry.cylinders = "2610"
ddb.geometry.heads = "255"
ddb.geometry.sectors = "63"
ddb.adapterType = "lsilogic"
Now the file is ready to be used by other virtual machines. Notice that the files in this directory do not make a virtual machine. Only the storage part is here.
Step 3. Make the disks read-only
We need to make sure that the base disks are not modified. So, we remove the "w" attribute from all the files in the base directory.
$ chmod a-w ub_srv_base/*s0*
Step 4. Remove the original virtual machine
Make a copy if you want. And actually having a backup of the base disk directory is a very good idea. Compress it and save it to a good location. But remove the virtual machine from Fusion. This will avoid confusion later on.
Do it many times - Create a clone
This process looks frightfully long, especially if you count the images below, but in reality it's very quick and painless. Once you get familiar with it, you will be cloning virtual machines in no time at all.
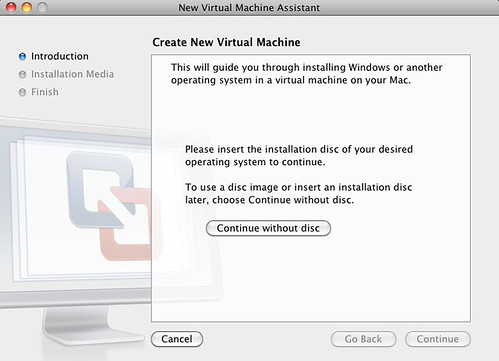
Back in VMWare Fusion, select "create a new Virtual Machine".
Make sure that you don't have the Ubuntu CD in your read DVD player. Click on "continue without disk".

Ignore the top options, and select "create a custom virtual machine".

Select the same operating system that was used for your base VM.
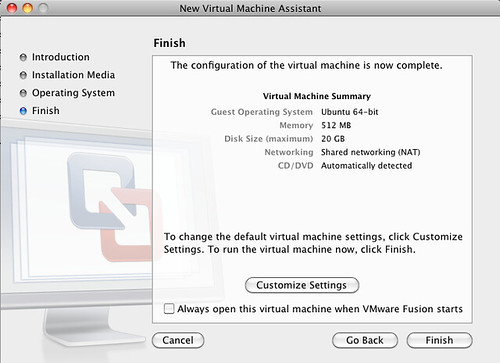
When the summary shows up, choose "Customize settings".
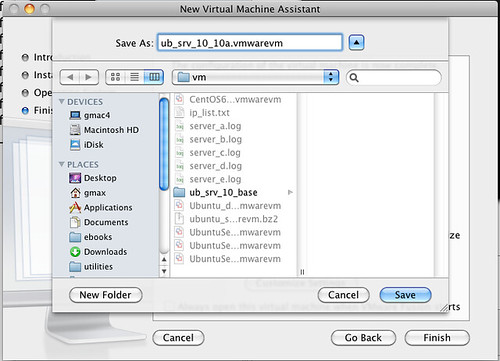
Save the VM with a sensible name. Since you will be creating many of the same kind, choose a pattern that you can recognize. In this case, I used the base name with an additional letter at the end to identify the server.

The disk is your main concern. The default settings want to create a 20 GB disk. Simply remove it.

When asked if you want to get rid of the disk completely, say yes, "move it to the trash".
Now, Very important, before you go to the next step. Use the command line, or a GUI, and copy the index .vmdk file from the base directory to the new virtual machine. I call it nd.vmdk (nd=new disk) but you can call it whatever you want. make sure that this file is not write protected.
|

Add another disk. Here's the first trick part. By default, Fusion wants to recreate the same disk that you have just removed. But notice that there is a drop down menu on the right side of the panel. Click on "choose existing disk".

Here you select the file that you have copied from the base directory. And now another tricky point. Make sure that you click on
"Share this virtual disk ...", otherwise VMWare will make a copy of your original disk files.

You can now change other parameters in the virtual machine, such as the amount of RAM and how many processors you want to use for it. I recommend unchecking the "connected" box next to the CDROM, to avoid a warning when more than a cloned VM work at the same time. You can always enable the CD later if you need it.
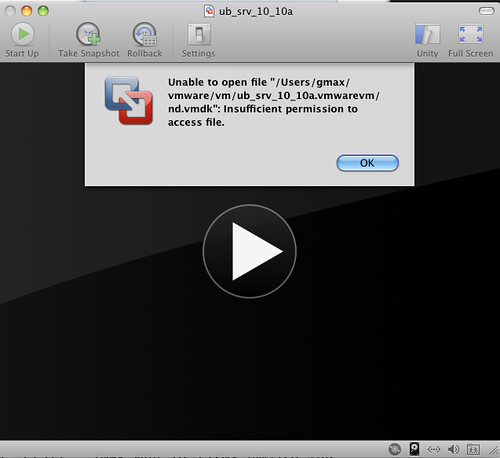
Now
Don't switch on your cloned virtual machine just yet. If you do, you get an incomprehensible message, where the VM complains about not being able to access the new disk file, while in reality it can't access the disks referred by that index file. This is where the precaution of write protecting the files comes handy. If you hadn't done that, the VM would access (and eventually modify) the virtual disk files, and possibly corrupt them. Instead, you need another step before having a functional clone.
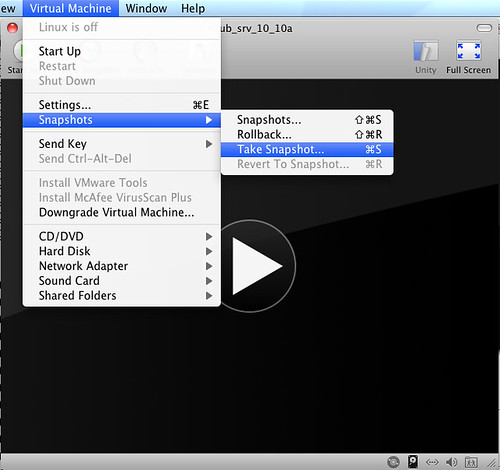
You need to create a snapshot. Once you have done that, the VM will write to the snapshot files all the deltas between your read-only disks and your VM final status.
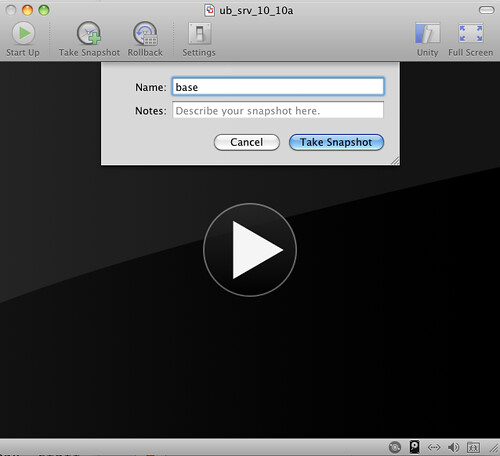
You can call the snapshot whatever you like.

Finally, you can run the virtual machine. If other virtual machines are running, it may warn you that some devices might not be available. Ignore this warning unless you know for sure that there is a unique resource that should not be shared (usually, there isn't).
Your virtual machine is ready to run. If you need to create three identical servers to simulate a cluster, and the original VM has 4GB of occupied storage, the operation won't cost you 16 GB, but just a few dozen MB:
$ du -sh ub_*/
21M ub_srv_10_10a.vmwarevm/
22M ub_srv_10_10b.vmwarevm/
21M ub_srv_10_10c.vmwarevm/
3.9G ub_srv_10_base/
Part II - Use your virtual machines from the command line
Although VMWare Fusion is handy for creating virtual machines, and for using GUI-based operating systems, it is less than desirable when you have several virtual machines with only text interface, and you want to use them from the command line, the same way you would do in most real life administration or QA operations.
No need for further hacking, in this case. You can manage your virtual machines from the command line, using an utility called
vmrun, which is located under /Library/Application Support/VMware Fusion/.
You can read the full manual in a lengthy PDF document that is available online (
Using vmrun to Control Virtual Machines), but here's the short story.
vmrun can start and stop a virtual machine. You just need to use it when the VMWare Fusion application is closed. For example:
$ vmrun start $HOME/vmware/vm/ub_srv_10_10a.vmwarevm/ub_srv_10_10a.vmx nogui
2010-11-19 14:58:49 no printer configured or none available
2010-11-19 14:58:49 adaptor daemon booted
2010-11-19 14:58:49 connector "vmlocal" booted
As part of my preparation of the virtual machine, I created a simple script that runs ifconfig and filters out the virtual machine IP to a file in the user's home.
Using this information, I can then run the following commands:
$ vmrun -gu qa -gp SECRETPWD runProgramInGuest \
$HOME/vmware/vm/ub_srv_10_10a.vmwarevm/ub_srv_10_10a.vmx \
/home/qa/bin/get_ip
$ vmrun -gu qa -gp SECRETPWD copyFileFromGuestToHost \
$HOME/vmware/vm/ub_srv_10_10a.vmwarevm/ub_srv_10_10a.vmx \
/home/qa/myip ./server_a_ip
$ cat server_a_ip
192.168.235.144
This is just a simple example of what you can do. Once you have the IP address (which the DHCP server could change), you can connect to your virtual machine via ssh and do what you need. When you have finished, you can switch off the VM, again without need of using the GUI:
$ vmrun stop ~/vmware/vm/ub_srv_10_10a.vmwarevm/ub_srv_10_10a.vmx 2010-11-19 15:11:25 adaptor daemon shut down
2010-11-19 15:11:25 connector "vmlocal" shut down
Happy (cloud) hacking!











