I am writing an article about some advanced replication features (coming soon), and I wanted to measure the speed of each specific architecture I am working with.
There seem to be no builtin MySQL solution for this particular problem, and thus I am using a hand made metrics tool, inspired by something that
Jeremy Zawodny suggested in his
High Performance MySQL a few years ago (see the relevant
chapter on replication with code).
The naive method would be to set a timestamp in a master table, and to measure the same record when it shows up in the slave. Unfortunately, (but correctly, I have to say!) this does not work, because the binary log includes information on the current timestamp, so that master and slave in the end have exactly the same contents.
Using a trigger in MySQL 5.0 seems promising, because you can set the timestamp tothe value of SYSDATE(), thus showing the different insertion times in master and slave. However, MySQL imestamps precision is limited to seconds. Therefore, if I insert a record at 12:00:00.9999 and the slave receives it at 12:00:01.0001, MySQL will record a difference of 1 second, even though in this case the difference would be just a couple of milliseconds.
With this in mind, I worked on Zawodny suggestion, which was still dealing with seconds, to imrove the method and measure the performance of a replication system with a much better accuracy (possibly microseconds).
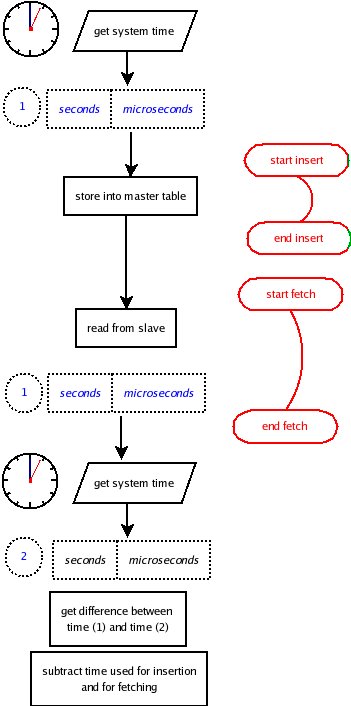
The schema works as follows (see the flow chart):
Get the system time in terms of seconds and microseconds (I am using Perl with the
Time::HiRes module, but any major language has a corresponding feature). Insert that time in a table on the master, measuring also the time spent for the insertion operation.
Immediately after, start looping on the slave to get that same record. When you do it, get again the system time (with microseconds precision) and subtract the time you got from the table.
For better precision subtract the time you used for inserting and for fetching, and you get the bare replication time.
Here is an example, using a record of 1000 bytes, in a loop that increases the size of the record by 1000 bytes at each step.
0 41 5 1143983120 992916 1143983120 997036
1 41 5 1143983121 207218 1143983121 211084
2 41 5 1143983121 420654 1143983121 424630
3 41 5 1143983121 634802 1143983121 638909
4 41 5 1143983121 849051 1143983121 853521
5 41 5 1143983122 65003 1143983122 67892
6 41 5 1143983122 279944 1143983122 282933
7 41 5 1143983122 493895 1143983122 498320
8 41 5 1143983122 710443 1143983122 715032
9 41 5 1143983122 927867 1143983122 932013
10 41 5 1143983123 145376 1143983123 149648
This is the raw output used for debugging. The first colum is the step. The second is the ID retrieved from the record, the third one is the sequence number (I inserted 5 records for each steps, and asked to fetch the record with sequence no. 5).
The fourth and fifth columns are the system time that was stored in the table. The remaining two columns are the system time as recorded at fetch time.
With the above data, we can produce a listing of the actual raplication times, in human-readable format.
loop data size master insert slave retrieval total repl. time bare time
---- --------- ------------- --------------- ---------------- ---------
1 1000 0.001655 0.000859 0.004120 0.001606
2 1000 0.001643 0.001268 0.003866 0.000955
3 2000 0.001505 0.000850 0.003976 0.001621
4 3000 0.001604 0.000849 0.004107 0.001654
5 4000 0.001943 0.000851 0.004470 0.001676
6 5000 0.001853 0.000981 0.002889 0.000055
7 6000 0.001964 0.000968 0.002989 0.000057
8 7000 0.003285 0.001081 0.004425 0.000059
9 8000 0.001431 0.000851 0.004589 0.002307
10 9000 0.003076 0.001012 0.004146 0.000058
11 10000 0.001282 0.001600 0.004272 0.001390
So the average replication time is, in this case, 0.001040 seconds.
For this test, I was using a sandbox environment, where both master and slave are in the same server. Thus there is some slight overhead due to the fact that one CPU is handling two instances of MySQL, and the same disk is hosting two logs (binary on the master, relay-log on the slave) in addition to the actual tables.
Using a real production replication, these times go down to an average of about 0.000500 seconds. It depends on several factors, from the speed of your networking equipment to the sheer power of your boxes.
Anyway, this is a tool that can be useful sometimes. You can get the source code from MySQL Forge snippets.
Update Since the Forge is being decomissioned, I add the source code here.
#!/usr/bin/perl
use strict;
use warnings;
use Data::Dumper;
use DBI;
use Time::HiRes qw/ usleep gettimeofday tv_interval/;
use English qw( -no_match_vars );
my $username1 = 'user1';
my $password1 = 'user2';
my $username2 = 'pass1';
my $password2 = 'pass2';
my $host1 = 'host_IP1';
my $host2 = 'host_IP2';
my $port1 = '3306';
my $port2 = '3306';
my $dbh1=DBI->connect("dbi:mysql:test;host=$host1;port=$port1",
$username1, $password1,
{RaiseError => 1})
or die "Can't connect: $DBI::errstr\n";
my $dbh2=DBI->connect("dbi:mysql:test;host=$host2;port=$port2",
$username2, $password2,
{RaiseError => 1})
or die "Can't connect: $DBI::errstr\n";
my $loops = 10; # how many times we loop (with size increase)
my $num_of_inserts = 5; # how many records we insert for each loop
my $initial_blob_size = 1_000; # how big is the record we start with
my $replica_db = 'test'; # which database we use for testing
my $master_dbh = $dbh1;
my $slave_dbh = $dbh2;
my ( $exists_db ) = $master_dbh->selectrow_array(qq{SHOW DATABASES LIKE '$replica_db'});
unless ($exists_db) {
eval {$master_dbh->do(qq{CREATE DATABASE $replica_db}) };
if ( $EVAL_ERROR ) {
die "execution error $DBI::errstr\n";
}
}
#
# creating the measurement table
#
eval {
$master_dbh->do( qq{
CREATE DATABASE IF NOT EXISTS $replica_db});
$master_dbh->do( qq{
USE $replica_db } );
$master_dbh->do( qq{
DROP TABLE IF EXISTS replica_speed });
$master_dbh->do( qq{
CREATE TABLE replica_speed (
id int(11) NOT NULL auto_increment,
insert_sequence int not null,
seconds bigint(20) default NULL,
microseconds bigint(20) default NULL,
ts timestamp(14) NOT NULL,
big_one longtext,
PRIMARY KEY (`id`),
KEY insert_sequence (insert_sequence)
)
} );
};
if ($EVAL_ERROR) {
die "table creation error $DBI::errstr\n";
}
#
# give some time to the table creation to get replicated
#
usleep(200_000);
my $insert_query = qq{
INSERT INTO $replica_db.replica_speed
(insert_sequence, seconds, microseconds, big_one)
VALUES ( ?, ?, ?, ?) };
my $retrieve_query = qq{
SELECT seconds, microseconds, id, insert_sequence
FROM $replica_db.replica_speed
WHERE insert_sequence = ?
};
my $slave_sth = $slave_dbh->prepare($retrieve_query);
#
# checking max_allowed_packet to make sure that we are not
# exceeding the limits
#
my ( undef, $master_max_allowed_packet) = $master_dbh->selectrow_array(
qq{ SHOW VARIABLES LIKE "max_allowed_packet" } );
my ( undef, $slave_max_allowed_packet) = $slave_dbh->selectrow_array(
qq{ SHOW VARIABLES LIKE "max_allowed_packet" } );
my $max_allowed_packet = $master_max_allowed_packet;
if ( $slave_max_allowed_packet < $master_max_allowed_packet) {
$max_allowed_packet = $slave_max_allowed_packet;
}
my @results = ();
LOOP:
for my $loopcount (0 .. $loops )
{
usleep(200_000);
#
# let's start with an empty table
#
$master_dbh->do( qq{ TRUNCATE $replica_db.replica_speed } );
my $size = $initial_blob_size * ($loopcount || 1);
if ($size > $max_allowed_packet) {
$size = $max_allowed_packet - 1000;
}
my $master_insert_time = 0.0;
my $big_blob = 'a' x $size;
#
# inserting several records in the master
#
for my $sequence (1 .. $num_of_inserts ) {
my ( $secs, $msecs ) = gettimeofday();
$master_dbh->do($insert_query, undef, $sequence, $secs, $msecs, $big_blob);
$master_insert_time = tv_interval( [$secs, $msecs], [gettimeofday()]);
}
my $replication_delay = 0;
my $total_retrieval_time = 0;
my $baredelay = undef;
#
# fetching data from the slave
#
RETRIEVAL:
while ( ! $replication_delay ) # waiting for data to arrive from master to slave
{
my $retrieval_start_time = [gettimeofday()];
$slave_sth->execute( $num_of_inserts);
my $info = $slave_sth->fetchrow_arrayref();
my $retrieval_stop_time = [gettimeofday()];
my $retrieval_time = 0.0;
$retrieval_time = tv_interval(
$retrieval_start_time,
$retrieval_stop_time);
next RETRIEVAL unless $info->[0];
#
# retrieval time is counted only after a successful fetch
#
$total_retrieval_time += $retrieval_time;
$replication_delay = tv_interval( [$info->[0], $info->[1]], $retrieval_stop_time);
$baredelay = $replication_delay - $total_retrieval_time - $master_insert_time;
printf "%4d %5d %5d %12d %12d %12d %12d\n",
$loopcount, $info->[2], $info->[3] , $info->[0] , $info->[1] ,
$retrieval_stop_time->[0], $retrieval_stop_time->[1];
}
push @results,
{
data_size => $size,
master_insert_time => $master_insert_time,
slave_retrieval_time => $total_retrieval_time,
replication_time => $replication_delay,
bare_replication_time => $baredelay,
}
}
#
# displaying results
#
my @header_sizes = qw(4 9 13 15 16 9);
my @headers = ('loop', 'data size', 'master insert', 'slave retrieval', 'total repl. time', 'bare time');
printf "%s %s %s %s %s %s\n" , @headers;
printf "%s %s %s %s %s %s\n" , map { '-' x $_ } @header_sizes;
my $count = 0;
for my $res (@results)
{
printf "%4d %9d %13.6f %15.6f %16.6f %9.6f\n" , ++$count,
map { $res->{$_} }
qw/data_size master_insert_time slave_retrieval_time replication_time bare_replication_time/;
}
Comments welcome.